Pokud naše práce vyžaduje získávání velkého množství dat z obsahu webových stránek, lze namísto opakujícího používání CTRL + C, CTRL + V využít funkce importxml() v google spreadsheets a obsah jednotlivých stránek importovat do jednotlivých buněk v nově vytvořené tabulce.
Funkce funguje velice jednoduše, do prvního parametru se vloží URL adresa, ve druhém parametru se vloží cesta skzre zdrojový kód k textu, který chceme naimportovat. V našem příkladu ukážu jak získávat informace z jednotlivých článků publikačního webu sport.cz.
Nejdříve se rovnou podívejte na výsledek.
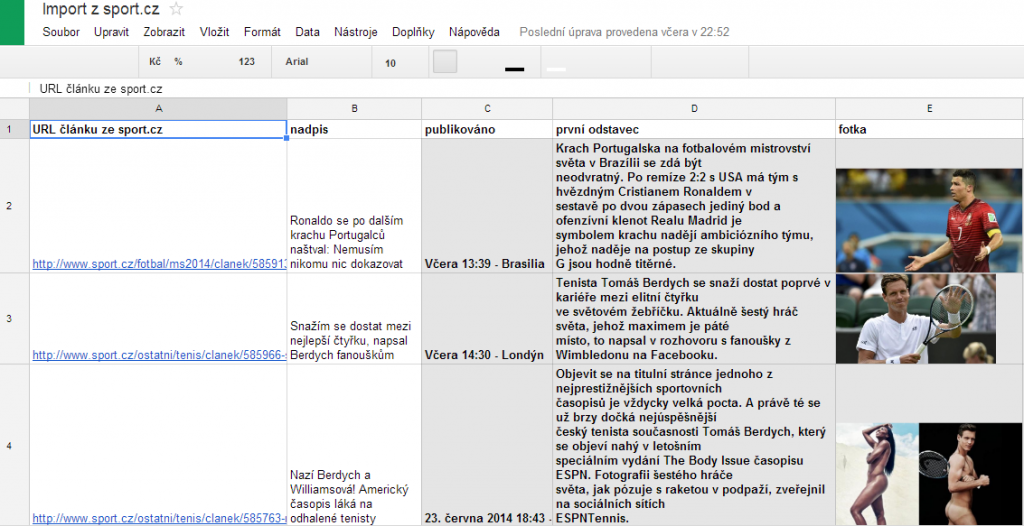 (pokud chcete s danou verzí pracovat, vytvořte si vlastní kopii dokumentu: Soubor > vytvořit kopii)
(pokud chcete s danou verzí pracovat, vytvořte si vlastní kopii dokumentu: Soubor > vytvořit kopii)
V buňce A2 je url adresa článku. Jako druhý parametr je cesta z textu z konkrétního tagu, my chceme zjistit nadpis, který se nachází v tagu <h1 >, který je na této webové stránce pouze jednou, takže lze nadpis získat tímto jednoduchým zápisem:
=IMPORTXML(A2;"//h1")
Informaci o datumu publikace článku jsme si ze zdrojového kódu zjistili, že se nachází v tagu <span class=“date“>, který má třídu date, to zjistíme tímto zápisem.
=IMPORTXML(A2;"//span[@class='date']")
Úvodní slovo se nachází v divu s parametrem id=“perex“, to zjistíme tímto zápisem:
=IMPORTXML($A2;"//div[@id='perex']")
Více informací o funkci importxml() najdete zde: https://support.google.com/docs/answer/3093342?rd=1
Pro vložení obrázku je nutné použít funkci image(), kam se do parametru vloží url adresa obrázku. URL adresa obrázku lze mechanicky generovat opět funkcí importxml(). Ze zdrojového kódu článku sport.cz víme, že se obrázek nachází vždy v divu s parametrem ID main-caption, tam nacházíme tag img a zjištujeme hodnotu parametru src tímto zápisem.
=IMAGE(IMPORTXML($A2;"//div[@id='main-caption']/img/@src")) '
Více informací o funkci image() naleznete zde: https://support.google.com/docs/answer/3093333?rd=1
Využívání funce importxml() si lze ušetřit spoustu času a ten věnovat detailní analýze, zpracování a vyhodnocení nově získaných dat. U rozsáhlejších prací se bude také hodit funkce split(), která slouží k rozdělení obsahu dané buňky na základě předem definovaného znaku, nebo naopak funkce concatenate(), která umí naopak sloučit obsah dvou buněk.
Další zdroje, které se mohou hodit k problematice získávání dat z webových stránek
